Оценка параметров модели уравнения множественной регрессии
В реальных ситуациях поведение зависимой переменной невозможно объяснить только с помощью одной зависимой переменной. Лучшее объяснение обычно дают несколько независимых переменных. Регрессионная модель, включающая несколько независимых переменных, называется множественной регрессией. Идея вывода коэффициентов множественной регрессии сходна с парной, но обычное алгебраическое их представление и вывод становятся весьма громоздкими. Для современных вычислительных алгоритмов и наглядного представления действий с уравнением множественной регрессии используется матричная алгебра. Матричная алгебра делает возможным представление операций над матрицами аналогичным операциям над отдельными числами и, тем самым определяет свойства регрессии в ясных и сжатых терминах.
Пусть имеется набор из n наблюдений с зависимой переменной Y , k объясняющими переменными X 1 , X 2 ,..., X k . Можно записать уравнение множественной регрессии следующим образом:
В терминах массива исходных данных это выглядит так:
=

 (3.2).
(3.2).
Коэффициенты
и параметры распределения
неизвестны. Наша задача состоит в
получении этих неизвестных. Уравнения,
входящие в (3.2), в
 матричной
форме имеют вид:
матричной
форме имеют вид:
Y = X + , (3.3)
где Y – вектор вида (y 1 ,y 2 , … ,y n) t
X – матрица, первый столбец которой составляют n единиц, а последующие k столбцов x ij , i = 1,n;
- вектор коэффициентов множественной регрессии;
- вектор случайной составляющей.
Чтобы продвинуться к цели оценивания вектора коэффициентов , необходимо принять несколько предположений относительно того, как генерируются наблюдения, содержащиеся в (3.1):
E ( ) = 0 ; (3.а)
E ( ) = 2 I n ; (3.б)
X – множество фиксированных чисел; (3.в)
(X ) = k < n . (3.г)
Первая гипотеза означает, что E ( i ) = 0 для всех i , то есть переменные i имеют нулевую среднюю. Предположение (3.б) – компактная запись второй очень важной гипотезы. Так как – вектор-столбец размерности n 1, а – вектор-строка, произведение – симметрическая матрица порядка n и

E
(
 )
E
(
1
2
)
...
E
(
1
n
)
2
0
... 0
)
E
(
1
2
)
...
E
(
1
n
)
2
0
... 0
E
(
)
=
E
(
2
1
)
E
(
 )
...
E
(
2
n
)
= 0
2
...
0
)
...
E
(
2
n
)
= 0
2
...
0
E
(
n
1
)
E
(
n
2
)
...
E
(
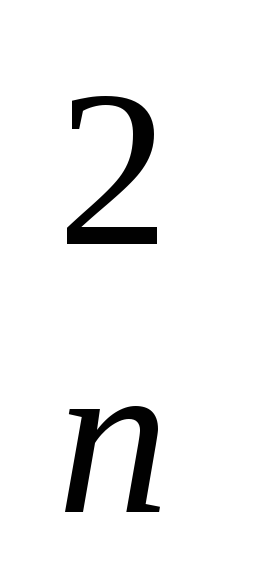 )
0 0 ...
2
)
0 0 ...
2
Элементы, стоящие на главной диагонали, свидетельствуют о том, что E( i 2 ) = 2 для всех i . Это означает, что все i имеют постоянную дисперсию 2 – свойство, в связи с которым говорят о гомоскедастичности. Элементы, не стоящие на главной диагонали, дают нам E( t t+s ) = 0 для s 0, так что значения i попарно некоррелированы. Гипотеза (3.в), в силу которой матрица X образована из фиксированных (неслучайных) чисел, означает, что в повторяющихся выборочных наблюдениях единственным источником случайных возмущений вектора Y являются случайные возмущения вектора , и поэтому свойства наших оценок и критериев обусловлены матрицей наблюдений X . Последнее предположение относительно матрицы X , ранг которой принимается равным k , означает, что число наблюдений превышает число параметров (иначе невозможна оценка этих параметров), и что не существует строгой зависимости между объясняющими переменными. Это соглашение простирается на все переменные X j , включая переменную X 0 , значение которой всегда равно единице, что соответствует первому столбцу матрицы X .
Оценка регрессионной модели с коэффициентами b 0 , b 1 ,…,b k , которые являются оценками неизвестных параметров 0 , 1 ,…, k и наблюдаемыми ошибками e , которые являются оценками ненаблюдаемых , может быть записана в матричной форме следующим образом

 (3.4).
(3.4).
При
использовании правил матричного сложения
и умножения отношения
между возможно большими массивами чисел
могут быть записаны несколькими
символами. Используя правило
транспонирования:A
=
транспонированной A
,
мы можем представить ряд других
результатов. Система нормальных уравнений
(для регрессии с любым числом переменных
и наблюдений) в матричном формате
записывается так:
отношения
между возможно большими массивами чисел
могут быть записаны несколькими
символами. Используя правило
транспонирования:A
=
транспонированной A
,
мы можем представить ряд других
результатов. Система нормальных уравнений
(для регрессии с любым числом переменных
и наблюдений) в матричном формате
записывается так:
Х Хb = Х Y (3.5).
Используя правило получения обратной матрицы: A -1 = инверсия A, мы можем решить систему нормальных уравнений путем перемножения каждой стороны уравнения (3.5) с матрицей (Х Х) -1 :
(Х Х) -1 (Х Х)b = (Х Х) -1 X Y
Ib = (Х Х) -1 X Y
Где I – матрица идентификации (единичная матрица), являющаяся результатом умножения матрицы на обратную. Поскольку Ib=b , мы получаем решение нормальных уравнений в терминах метода наименьших квадратов для оценки вектора b :
b = (Х Х) -1 X Y (3.6).
Отсюда, для любого числа переменных и значений данных, мы получаем вектор параметров оценки, транспонирование которых есть b 0 , b 1 ,…,b k, как результат матричных операций над уравнением (3.6).
Представим
теперь и другие результаты. Предсказанное
значение Y, которое мы обозначаем как
 ,
корреспондирует с наблюдаемыми значениями
Y как:
,
корреспондирует с наблюдаемыми значениями
Y как: (3.7).
(3.7).
Поскольку b = (Х Х) -1 X Y , то мы можем записать подогнанные значения в терминах трансформации наблюдаемых значений:
 (3.8).
(3.8).
Обозначив
 ,
можем записать
,
можем записать .
.
Все матричные вычисления осуществляются в пакетах программ по регрессионному анализу.
Матрица ковариации коэффициентов оценки b задана как:
 ,
это следует из того, что
,
это следует из того, что
Поскольку
 неизвестно и оценивается МНК, то мы
имеем оценку ковариации матрицыb
как:
неизвестно и оценивается МНК, то мы
имеем оценку ковариации матрицыb
как:
 (3.9).
(3.9).
Если
мы обозначим матрицу С
как
 ,
то оценка стандартной ошибки каждогоb
i
есть
,
то оценка стандартной ошибки каждогоb
i
есть
 (3.10),
(3.10),
где С ii – диагональ матрицы.
Спецификация модели. Ошибки спецификации
Журнал «Quarterly Review of Economics and Business» приводит данные о вариации дохода кредитных организаций США за период 25 лет в зависимости от изменений годовой ставки по сберегательным депозитам и числа кредитных учреждений. Логично предположить, что, при прочих равных условиях, предельный доход будет положительно связан с процентной ставкой по депозиту и отрицательно с числом кредитных учреждений. Построим модель следующего вида:
 ,
,
 –прибыль
кредитных организаций (в процентах);
–прибыль
кредитных организаций (в процентах);
 –чистый
доход на один доллар депозита;
–чистый
доход на один доллар депозита;
 –число
кредитных учреждений.
–число
кредитных учреждений.
Исходные данные для модели:
|
|
|
|
||



Анализ данных начинаем с расчета дескриптивных статистик:
Таблица 3.1. Дескриптивныестатистики
Сравнивая значения средних величин и стандартных отклонений, находим коэффициент вариации, значения которого свидетельствуют о том, что уровень варьирования признаков находится в допустимых пределах (< 0,35). Значения коэффициентов асимметрии и эксцесса указывают на отсутствие значимой скошенности и остро-(плоско-) вершинности фактического распределения признаков по сравнению с их нормальным распределением. По результатам анализа дескриптивных статистик можно сделать вывод, что совокупность признаков – однородна и для её изучения можно использовать метод наименьших квадратов (МНК) и вероятностные методы оценки статистических гипотез.
Перед построением модели множественной регрессии рассчитаем значения линейных коэффициентов парной корреляции. Они представлены в матрице парных коэффициентов (таблица 3.2) и определяют тесноту парных зависимостей анализируемыми между переменными.
Таблица 3.2. Коэффициенты парной линейной корреляции Пирсона
|
|
|
|
|
|
| |||
|
| |||
|
| |||
|
В скобках: Prob > |R| under Ho: Rho=0 / N = 25 |
|||






Коэффициент
корреляции между
 и
и свидетельствует о значительной и
статистически существенной обратной
связи между прибылью кредитных учреждений,
годовой ставкой по депозитам и числом
кредитных учреждений. Знак коэффициента
корреляции между прибылью и ставкой по
депозиту имеет отрицательный знак, что
противоречит нашим первоначальным
предположениям, связь между годовой
ставкой по депозитам и числом кредитных
учреждений – положительная и высокая.
свидетельствует о значительной и
статистически существенной обратной
связи между прибылью кредитных учреждений,
годовой ставкой по депозитам и числом
кредитных учреждений. Знак коэффициента
корреляции между прибылью и ставкой по
депозиту имеет отрицательный знак, что
противоречит нашим первоначальным
предположениям, связь между годовой
ставкой по депозитам и числом кредитных
учреждений – положительная и высокая.
Если мы обратимся к исходным данным, то увидим, что в течение исследуемого периода число кредитных учреждений возрастало, что могло привести к росту конкуренции и увеличению предельной ставки до такого уровня, который и повлек за собой снижение прибыли.
Приведенные в таблице 3.3 линейные коэффициенты частной корреляции оценивают тесноту связи значений двух переменных, исключая влияние всех других переменных, представленных в уравнении множественной регрессии.
Таблица 3.3. Коэффициенты частной корреляции
|
|
|
|
|
|
| |||
|
| |||
|
| |||
|
В скобках: Prob > |R| under Ho: Rho=0 / N = 10 |
|||


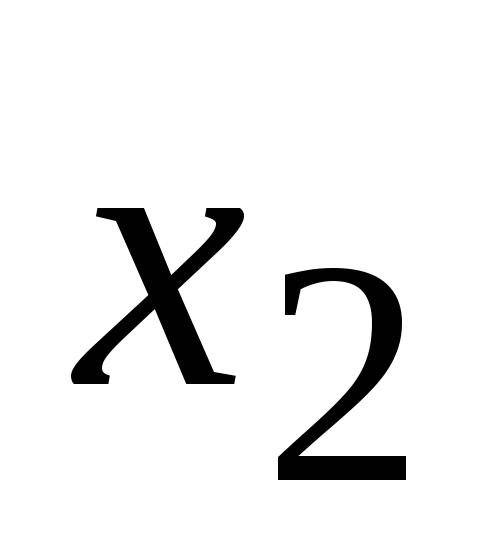


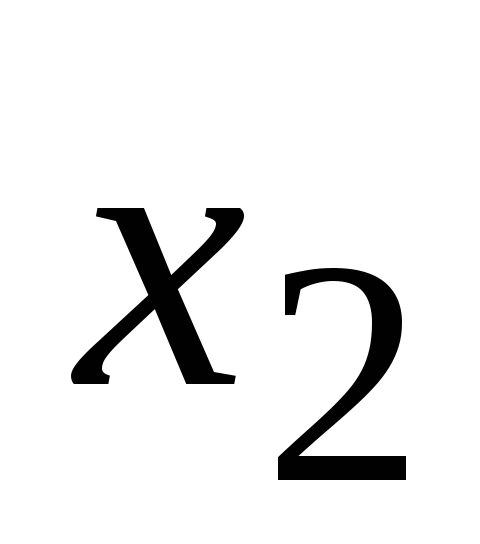
Коэффициенты
частной корреляции дают более точную
характеристику тесноты зависимости
двух признаков, чем коэффициенты парной
корреляции, так как «очищают» парную
зависимость от взаимодействия данной
пары переменных с другими переменными,
представленными в модели. Наиболее
тесно связаны
 и
и ,
, .
Другие взаимосвязи существенно слабее.
При сравнении коэффициентов парной и
частной корреляции видно, что из-за
влияния межфакторной зависимости между
.
Другие взаимосвязи существенно слабее.
При сравнении коэффициентов парной и
частной корреляции видно, что из-за
влияния межфакторной зависимости между и
и происходит некоторое завышение оценки
тесноты связи между переменными.
происходит некоторое завышение оценки
тесноты связи между переменными.
Результаты построения уравнения множественной регрессии представлены в таблице 3.4.
Таблица 3.4. Результаты построения модели множественной регрессии
|
Независимые переменные |
Коэффициенты |
Стандартные ошибки |
t - статистики |
Вероятность случайного значения |
||
|
Константа | ||||||
|
x 1 | ||||||
|
x 2 | ||||||
|
R 2 = 0,87 | ||||||
|
R 2 adj =0,85 | ||||||
|
F = 70,66 |
Prob > F = 0,0001 | |||||
Уравнение имеет вид:
y = 1,5645+ 0,2372x 1 - 0,00021x 2.
Интерпретация коэффициентов регрессии следующая:
 оценивает
агрегированное влияние прочих (кроме
учтенных в модели х
1
и х
2
)
факторов на результат
y
;
оценивает
агрегированное влияние прочих (кроме
учтенных в модели х
1
и х
2
)
факторов на результат
y
;
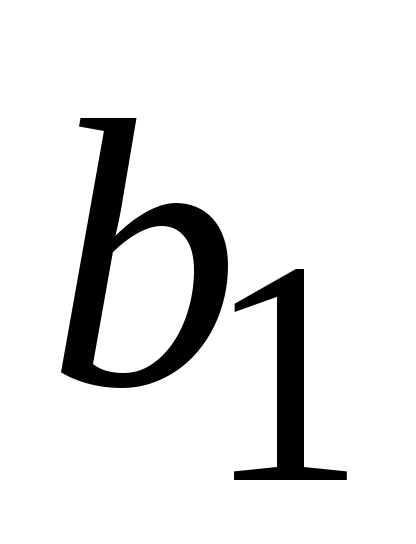 и
и
 указывают на сколько единиц изменитсяy
при изменении х
1
и х
2
на единицу
их значений. Для заданного числа
кредитных учреждений, увеличение на 1%
годовой ставки по депозитам ведет к
ожидаемому увеличению на 0,237% в годовом
доходе этих учреждений. При заданном
уровне годового дохода на один доллар
депозита, каждое новое кредитное
учреждение снижает норму прибыли для
всех на 0,0002%.
указывают на сколько единиц изменитсяy
при изменении х
1
и х
2
на единицу
их значений. Для заданного числа
кредитных учреждений, увеличение на 1%
годовой ставки по депозитам ведет к
ожидаемому увеличению на 0,237% в годовом
доходе этих учреждений. При заданном
уровне годового дохода на один доллар
депозита, каждое новое кредитное
учреждение снижает норму прибыли для
всех на 0,0002%.
Значения стандартной ошибки параметров представлены в графе 3 таблицы 3.4: Они показывают, какое значение данной характеристики сформировалось под влиянием случайных факторов. Их значения используются для расчетаt -критерия Стьюдента (графа 4)
 19,705;
19,705;
 =4,269;
=4,269; =-7,772.
=-7,772.
Если значения t -критерия больше 2, то можно сделать вывод о существенности влияния данного значения параметра, которое формируется под влиянием неслучайных причин.
Зачастую
интерпретация результатов регрессии
более наглядна, если произведен расчет
частных коэффициентов эластичности.
Частные коэффициенты эластичности
 показывают, на сколько процентов от
значения своей средней
показывают, на сколько процентов от
значения своей средней изменяется результат при изменении
фактораx
j
на 1% от своей средней
изменяется результат при изменении
фактораx
j
на 1% от своей средней
 и при фиксированном воздействии наy
прочих факторов, включенных в уравнение
регрессии. Для линейной зависимости
и при фиксированном воздействии наy
прочих факторов, включенных в уравнение
регрессии. Для линейной зависимости
 ,
где
,
где коэффициент регрессии при
коэффициент регрессии при в уравнении множественной регрессии.
Здесь
в уравнении множественной регрессии.
Здесь


Нескорректированный
множественный коэффициент детерминации
 оценивает долю вариации результата за
счет представленных в уравнении факторов
в общей вариации результата. В нашем
примере эта доля составляет 86,53% и
указывает на весьма высокую степень
обусловленности вариации результата
вариацией факторов. Иными словами, на
весьма тесную связь факторов с результатом.
оценивает долю вариации результата за
счет представленных в уравнении факторов
в общей вариации результата. В нашем
примере эта доля составляет 86,53% и
указывает на весьма высокую степень
обусловленности вариации результата
вариацией факторов. Иными словами, на
весьма тесную связь факторов с результатом.
Скорректированный
 (гдеn
–
число наблюдений, m
– число переменных) определяет тесноту
связи с учетом степеней свободы общей
и остаточной дисперсий. Он дает такую
оценку тесноты связи, которая не зависит
от числа факторов в модели и поэтому
может сравниваться по разныммоделям
с разным числом факторов. Оба коэффициента
указывают на весьма высокую
детерминированность результата y
в модели факторами x
1
и x
2
.
(гдеn
–
число наблюдений, m
– число переменных) определяет тесноту
связи с учетом степеней свободы общей
и остаточной дисперсий. Он дает такую
оценку тесноты связи, которая не зависит
от числа факторов в модели и поэтому
может сравниваться по разныммоделям
с разным числом факторов. Оба коэффициента
указывают на весьма высокую
детерминированность результата y
в модели факторами x
1
и x
2
.
Для проведения дисперсионного анализа и расчета фактического значения F -критерия заполним таблицу результатов дисперсионного анализа, общий вид которой:
|
Сумма квадратов |
Число степеней свободы |
Дисперсия |
F-критерий |
|
|
За счет регрессии |
С факт. (SSR ) |
|
|
|
|
Остаточная |
С ост. (SSE ) |
| ||
|
С общ. (SST ) |
n -1 |

 (MSR)
(MSR)

 (MSE)
(MSE)
Таблица 3.5. Дисперсионный анализ модели множественной регрессии
|
Колеблемость результативного признака |
Сумма квадратов |
Число степеней свободы |
Дисперсия |
F-критерий |
|
За счет регрессии | ||||
|
Остаточная | ||||
Оценку
надежности уравнения регрессии в целом,
его параметров и показателя тесноты
связи
 даетF
-критерий
Фишера:
даетF
-критерий
Фишера:
Вероятность случайного значения F - критерия составляет 0,0001, что значительно меньше 0,05. Следовательно, полученное значение неслучайно, оно сформировалось под влиянием существенных факторов. То есть подтверждается статистическая значимость всего уравнения, его параметров и показателя тесноты связи – коэффициента множественной корреляции.
Прогноз
по модели множественной регрессии
осуществляется по тому же принципу, что
и для парной регрессии. Для получения
прогнозных значений мы подставляем
значения х
i
в уравнение
для получения значения .
Предположим, что мы хотим узнать ожидаемую
норму прибыли, при условии, что годовая
ставка депозита составила 3,97%, а число
кредитных учреждений – 7115:
.
Предположим, что мы хотим узнать ожидаемую
норму прибыли, при условии, что годовая
ставка депозита составила 3,97%, а число
кредитных учреждений – 7115:
Качество
прогноза – неплохое, поскольку в исходных
данных таким значениям независимых
переменных соответствует значение
 равное
0,70. Мы так же можем вычислить интервал
прогноза как
равное
0,70. Мы так же можем вычислить интервал
прогноза как -
доверительный интервал для ожидаемого
значения
-
доверительный интервал для ожидаемого
значения при заданных значениях независимых
переменных:
при заданных значениях независимых
переменных:
где
MSE – остаточная дисперсия, а стандартная
ошибка
 для случая нескольких независимых
переменных имеет достаточно сложное
выражение, которое мы здесь не приводим.
для случая нескольких независимых
переменных имеет достаточно сложное
выражение, которое мы здесь не приводим. доверительный интервал для значения
доверительный интервал для значения при средних значениях независимых
переменных имеет вид:
при средних значениях независимых
переменных имеет вид:

Большинство пакетов программ рассчитывают доверительные интервалы.
Гетероскедакстичность
Один из основных методов проверки качества подгонки линии регрессии по отношению к эмпирическим данным – анализ остатков модели.
Остатки
или оценка ошибки регрессии  могут быть определены как разница между
наблюдаемыми y
i
и предсказанными значениями y
i
зависимой переменной для заданных
значений x i ,
то есть
могут быть определены как разница между
наблюдаемыми y
i
и предсказанными значениями y
i
зависимой переменной для заданных
значений x i ,
то есть  .
При
построении регрессионной модели мы
предполагаем, что остатки её -
некоррелированные случайные величины,
подчиняющиеся нормальному распределению
со средней равной нулю и постоянной
дисперсией
.
При
построении регрессионной модели мы
предполагаем, что остатки её -
некоррелированные случайные величины,
подчиняющиеся нормальному распределению
со средней равной нулю и постоянной
дисперсией  .
.
Анализ остатков позволяет выяснить:
1. Подтверждается или нет предположение о нормальности?
2. Является
ли дисперсия остатков  постоянной
величиной?
постоянной
величиной?
3. Является ли распределение данных вокруг линии регрессии равномерным?
Кроме того, важным моментом анализа, является проверка того - есть ли в модели пропущенные переменные, которые должны быть включены в модель.
Для данных, упорядоченных во времени, анализ остатков может обнаружить имеет ли факт упорядочения влияние на модель, если да, то переменная, задающая временной порядок должна быть добавлена в модель.
И окончательно, анализ остатков обнаруживает верность предположения о некоррелированности остатков.
Самый простой способ анализа остатков – графический. В этом случае на оси Y откладываются значения остатков. Обычно используются, так называемые, стандартизованные (стандартные) остатки:
 ,
(3.11),
,
(3.11),
где
 ,
,
а

В пакетах прикладных программ всегда предусмотрена процедура расчета и тестирования остатков и печати графиков остатков. Рассмотрим наиболее простые из них.
Предположение о гомоскедастичности можно проверить с помощью графика, на оси ординат которого откладывают значения стандартизованных остатков, а на оси абсцисс – значения Х. Рассмотрим гипотетический пример:


Модель с гетероскедастичностью Модель с гомоскедастичностью
Мы
видим, что с увеличением значений Х
увеличивается вариация остатков, то
есть мы наблюдаем эффект гетероскедастичности,
дефицит гомогенности (однородности) в
вариации Y для каждого уровня. На графике
определяем возрастают или убывают Х
или Y при возрастании или убывании
остатков. Если график не обнаруживает
зависимости между  и Х, то условие гомоскедастичности
выполняется.
и Х, то условие гомоскедастичности
выполняется.
Если условие гомоскедастичности не выполняется, то модель не годится для прогноза. Надо использовать взвешенный метод наименьших квадратов или ряд других методов, которые освещаются в более продвинутых курсах статистики и эконометрики, или преобразовывать данные.
График остатков может помочь и определить есть ли в модели пропущенные переменные. Например, мы собрали данные о потреблении мяса за 20 лет - Y и оцениваем зависимость этого потребления от душевых доходов населения Х 1 и региона проживания Х 2 . Данные упорядочены во времени. После того как построена модель, полезно построить график остатков относительно временных периодов.

Если график обнаруживает наличие тенденции в распределении остатков во времени, то в модель необходимо включить объясняющую переменную t. в дополнение к Х 1 и Х 2 . Это же относится и к любым другим переменным. Если есть тренд в графике остатков, то и переменная должна быть включена в модель наряду с другими уже включенными переменными.
График остатков позволяет определить отклонения от линейности в модели. Если взаимосвязь между Х и Y носит нелинейный характер, то параметры уравнения регрессии будут указывать на плохое качество подгонки. В таком случае остатки будут вначале большими и отрицательными, затем уменьшатся, а потом станут положительными и случайными. Они указывают на криволинейность и график остатков будет иметь вид:
Ситуация может быть исправлена добавлением в модель Х 2 .
Предположение о нормальности так же может быть проверено с помощью анализа остатков. Для этого по значениям стандартных остатков строится гистограмм частот. Если линия, проведенная через вершины многоугольника, напоминает кривую нормального распределения, то предположение о нормальности подтверждается.
Мультиколлинеарность, способы оценки и устранения
Для того, чтобы множественный регрессионный анализ, основанный на МНК, давал наилучшие результаты мы предполагаем, что значения Х -ов не являются случайными величинами и чтоx i в модели множественной регрессии не коррелированны. То есть каждая переменная содержит уникальную информацию оY , которая не содержится в другихx i . Когда такая идеальная ситуация имеет место, то мультиколлинеарность отсутствует. Полная коллинеарность появляется в случае, если одна изХ может быть точно выражена в терминах другой переменнойХ для всех элементов набора данных. На практике большинство ситуаций находится между этими двумя крайними случаями. Как правило, существует некоторая степень коллинеарности между независимыми переменными. Мера коллинеарности между двумя переменными есть корреляция между ними.
Оставим в стороне предположение о том, что x i не случайные величины и измерим корреляцию между ними. Когда две независимые переменные связаны высокой корреляцией, то мы говорим об эффекте мультиколлинеарности в процедуре регрессионной оценки параметров. В случае очень высокой коллинеарности процедура регрессионного анализа становится неэффективной, большинство пакетов ППП в этом случае выдают предупреждение или прекращают процедуру. Даже, если мы получим в таком ситуации оценки регрессионных коэффициентов, то их вариация (стандартная ошибка) будут очень малы.
Простое
объяснение мультиколлинеарности можно
дать в матричных терминах. В случае
полной мультиколлинеарности, колонки
матрицы х
-ов
– линейно зависимы. Полная
мультиколлинеарность означает, что по
крайней мере две из переменных х
i
зависят друг от друга. Из уравнения ()
видно, что это означает, что колонки
матрицы зависимы. Следовательно, матрица
 так же мультиколлинеарна и не может
быть инвертирована (её детерминант
равен нулю), то есть мы не можем вычислить
так же мультиколлинеарна и не может
быть инвертирована (её детерминант
равен нулю), то есть мы не можем вычислить и не можем получить вектор параметров
оценкиb
.
В случае, когда мультиколлинеарность
присутствует, но не полная, то матрица
– обращаемая, но не стабильная.
и не можем получить вектор параметров
оценкиb
.
В случае, когда мультиколлинеарность
присутствует, но не полная, то матрица
– обращаемая, но не стабильная.
Причинами мультиколлинеарности могут быть:
1) Способ сбора данных и отбора переменных в модель без учета их смысла и природы (учета возможных взаимосвязей между ними). Например, с помощью регрессии мы оцениваем влияние на размер жилья Y доходов семьи Х 1 и размера семьи Х 2 . Если мы соберем данные только среди семей большого размера и высокими доходами и не включим в выборку семьи малого размера и с небольшими доходами, то в результате получим модель с эффектом мультиколлинеарности. Решением проблемы в этом случае будет улучшение схемы выборки.
В случае, если переменные взаимодополняют друг друга, подгонка выборки не поможет. Решением проблемы здесь может быть исключение одной из переменных модели.
2) Другая причина мультиколлинеарности может состоять в высокой мощности X i . Например, для линеаризации модели мы вводим дополнительный термин X 2 в модель, которая содержит X i . Если разброс значений Х незначителен, то мы получим высокую мультиколлинеарность.
Каким бы ни был источник мультиколлинеарности, важно избежать его появления.
Мы уже говорили, что компьютерные пакеты обычно выдают предупреждение о мультиколлинеарности или даже останавливают вычисления. В случае не столь высокой коллинеарности компьютер выдаст нам регрессионное уравнение. Но вариация оценок будет близка к нулю. Существуют два основных метода, доступных во всех пакетах, которые помогут нам решить эту проблему.
Вычисление матрицы коэффициентов корреляции для всех независимых переменных. Например, матрица коэффициентов корреляции между переменными в примере из параграфа 3.2 (таблица 3.2) указывает на то, что коэффициент корреляции между х 1 и х 2 очень велик, то есть эти переменные содержат много идентичной информации о y и, следовательно, коллинеарны.
Надо заметить, что не существует единого правила, согласно которому есть некоторое пороговое значение коэффициента корреляции, после которого высокая корреляция может оказать отрицательный эффект на качество регрессии.
Мультиколлинеарность может иметь причиной более сложные взаимосвязи между переменными нежели парные корреляции между независимыми переменными. Это влечет за собой использование второго метода определения мультиколлинеарности, который называется “фактор инфляции вариации”.
Степень
мультиколлинеарности, представляемая
в регрессии переменной
 ,
когда переменные
,
когда переменные ,
, ,…,
,…, включены в регрессию, есть функция
множественной корреляции между
включены в регрессию, есть функция
множественной корреляции между и другими переменными
и другими переменными ,
, ,…,
,…, .
Предположим, что мы рассчитаем регрессию
не поy
,
а по
.
Предположим, что мы рассчитаем регрессию
не поy
,
а по
 ,
как зависимой переменной, и оставшимися
,
как зависимой переменной, и оставшимися как независимыми. Из этой регрессии мы
получимR
2
, значение которого – мера мультиколлинеарности
привносимой переменной
как независимыми. Из этой регрессии мы
получимR
2
, значение которого – мера мультиколлинеарности
привносимой переменной
 .
Повторим, что основная проблема
мультиколлинеарности – обесценивание
дисперсии оценок коэффициентов регрессии.
Для измерения эффекта мультиколлинеарности
используется показатель VIF “variation
inflation factor”, ассоциируемый с переменной
.
Повторим, что основная проблема
мультиколлинеарности – обесценивание
дисперсии оценок коэффициентов регрессии.
Для измерения эффекта мультиколлинеарности
используется показатель VIF “variation
inflation factor”, ассоциируемый с переменной :
:
 (3.12),
(3.12),
где
 – значение коэффициента множественной
корреляции, полученное для регрессора
– значение коэффициента множественной
корреляции, полученное для регрессора как зависимой переменной и остальных
переменных
как зависимой переменной и остальных
переменных .
.
Можно
показать, что VIF переменной
 равен отношению дисперсии коэффициентаb
h
в регрессии с y
как зависимой переменной и дисперсией
оценки b
h
в регрессии где
равен отношению дисперсии коэффициентаb
h
в регрессии с y
как зависимой переменной и дисперсией
оценки b
h
в регрессии где
 не коррелированна с другими переменными.
VIF – это фактор инфляции дисперсии
оценки по сравнению с той вариацией,
которая была бы, если бы
не коррелированна с другими переменными.
VIF – это фактор инфляции дисперсии
оценки по сравнению с той вариацией,
которая была бы, если бы не имел коллинеарности с другими x
переменными в регрессии. Графически
это можно изобразить так:
не имел коллинеарности с другими x
переменными в регрессии. Графически
это можно изобразить так:

Как
видно из рисунка 7, когда R
2
от
 увеличивается по отношению к другим
переменным от 0,9 до 1 VIF становится очень
большим. Значение VIF, например, равное
6 означает, что дисперсия регрессионных
коэфиициентовb
h
в 6 раз
больше той, что должна была бы быть при
полном отсутствии коллинеарности.
Исследователи используют VIF = 10 как
критическое правило для определения
является ли корреляция между независимыми
переменными слишком большой. В примере
из параграфа 3.2 значение VIF = 8,732.
увеличивается по отношению к другим
переменным от 0,9 до 1 VIF становится очень
большим. Значение VIF, например, равное
6 означает, что дисперсия регрессионных
коэфиициентовb
h
в 6 раз
больше той, что должна была бы быть при
полном отсутствии коллинеарности.
Исследователи используют VIF = 10 как
критическое правило для определения
является ли корреляция между независимыми
переменными слишком большой. В примере
из параграфа 3.2 значение VIF = 8,732.
Как еще можно обнаружить эффект мультиколлинеарности без расчета корреляционной матрицы и VIF.
Стандартная ошибка в регрессионных коэффициентах близка к нулю.
Мощность коэффициента регрессии не та, что Вы ожидали.
Знаки коэффициентов регрессии противоположны ожидаемым.
Добавление или удаление наблюдений в модель сильно изменяет значения оценок.
В некоторых ситуациях получается, что F – cущественно, а t – нет.
Насколько отрицательно сказывается эффект мультиколлинеарности на качестве модели? В дейсвительности проблема не столь страшна как кажется. Если мы используем уравнение для прогноза. То интерполяция результатов даст вполне надежные результаты. Эксторополяция приведет к значительным ошибкам. Здесь необходимы другие методы корректировки. Если мы хотим измерить влияние некоторых определенных перменных на Y, то здесь так же могут возникнуть проблемы.
Для решения проблемы мультиколлинеарности можно предпринять следующее:
Удалить коллинеарные переменные. Это не всегда возможно в эконометрических моделях. В этом случае необходимо использовать другие методы оценки (обобщенный метод наименьших квадратов).
Исправить выборку.
Изменить переменные.
Использовать гребневую регрессию.
Гетероскедастичность, способы выявления и устранения
Если остатки модели имеют постоянную дисперсию, они называются гомоскедастичными, но если они непостоянны, то гетероскедастичными.
Если условие гомоскедастичности не выполняется, то надо использовать взвешенный метод наименьших квадратов или ряд других методов, которые освещаются в более продвинутых курсах статистики и эконометрики, или преобразовывать данные.
Например, нас интересуют факторы, влияющие на выпуск продукции на предприятиях определенной отрасли. Мы собрали данные о величине фактического выпуска, численности работников и стоимости основных фондов (основного капитала) предприятий. Предприятия различаются по величине и мы вправе ожидать, что для тех из них, объем выпускаемой продукции в которых выше, термин ошибки в рамках постулируемой модели будет так же в среднем больше, чем для малых предприятий. Следовательно, вариация ошибки не будет одинаковой для всех предприятий, она, скорее всего, будет возрастающей функцией от размера предприятия. В такой модели оценки не будут эффективными. Обычные процедуры построения доверительных интервалов, проверки гипотез для этих коэффициентов не будут надежными. Поэтому важно знать приемы определения гетероскедастичности.
Влияние гетероскедастичности на оценку интервала прогнозирования и проверку гипотезы заключается в том, что хотя коэффициенты не смещены, дисперсии и, следовательно, стандартные ошибки этих коэффициентов будут смещены. Если смещение отрицательно, то стандартные ошибки оценки будут меньше, чем они должны быть, а критерий проверки будет больше, чем в реальности. Таким образом, мы можем сделать вывод, что коэффициент значим, когда он таковым не является. И наоборот, если смещение положительно, то стандартные ошибки оценки будут больше, чем они должны быть, а критерии проверки – меньше. Значит, мы можем принять нулевую гипотезу о значимости коэффициента регрессии, в то время как она должна быть отклонена.
Обсудим формальную процедуру определения гетероскедастичности, когда условие постоянства дисперсии нарушено.
Предположим,
что регрессионная модель связывает зависимую
переменную и с k
незавввисимыми переменными в наборе
из n
наблюдений.
Пусть
 - набор коэффициентов, полученных МНК
и теоретическое значение переменной
есть,
остатки модели:
- набор коэффициентов, полученных МНК
и теоретическое значение переменной
есть,
остатки модели: .
Нуль-гипотеза состоит в том. что остатки
имеют одинаковую дисперсию.
Альтернативная гипотеза состоит в том,
что их дисперсия зависит от ожидаемых
значений:.
Для проверки гипотезы проводим оценку
линейной регрессии. в которой зависимая
переменная есть квадрат ошибки, то есть
.
Нуль-гипотеза состоит в том. что остатки
имеют одинаковую дисперсию.
Альтернативная гипотеза состоит в том,
что их дисперсия зависит от ожидаемых
значений:.
Для проверки гипотезы проводим оценку
линейной регрессии. в которой зависимая
переменная есть квадрат ошибки, то есть ,
а независимая переменная – теоретическое
значение
,
а независимая переменная – теоретическое
значение .
Пусть
.
Пусть - коэффициент детерминации в этой
вспомогательной дисперсии. Тогда для
заданного уровня значимости
нуль-гипотеза отклоняется, если
- коэффициент детерминации в этой
вспомогательной дисперсии. Тогда для
заданного уровня значимости
нуль-гипотеза отклоняется, если
 больше чем
больше чем ,
где
,
где есть критическое значение СВ
есть критическое значение СВ с уровнем значимости
и одной степенью свободы.
с уровнем значимости
и одной степенью свободы.
В случае, если мы подтвердим гипотезу о том, что дисперсия ошибки регрессии не является постоянной величиной, то метод наименьших квадратов не приводит к наилучшей подгонке. Могут быть использованы различные способы подгонки, выбор альтернатив зависит от того, как дисперсия ошибки ведет себя с другими переменными. Чтобы решить проблему гетероскедастичности, нужно исследовать взаимосвязь между значением ошибки и переменными и трансформировать регрессионную модель так, чтобы она отражала эту взаимосвязь. Это может быть достигнуто посредством регрессии значений ошибок по различным формам функций переменной, которая приводит к гетероскедастичности.
Одна из возможностей устранения гетероскедастичности состоит в следующем. Предположим, что вероятность ошибки прямо пропорциональна квадрату ожидаемого значения зависимой переменной при заданных значениях независимой, так что
В
этом случае можно использовать простую
двухшаговую процедуру оценки параметров
модели. На первом шаге модель оценивается
при помощи МНК обычным способом и
формируется набор значений
 .
На втором шаге оценивается регрессионное
уравнение следующего вида:
.
На втором шаге оценивается регрессионное
уравнение следующего вида:
Где
 - ошибка дисперсии, которая будет
постоянной. Это уравнение будет
представлять регрессионную модель, к
которой зависимая переменная -
- ошибка дисперсии, которая будет
постоянной. Это уравнение будет
представлять регрессионную модель, к
которой зависимая переменная - ,
а независимые -
,
а независимые - .
Затем коэффициенты оцениваются МНК.
.
Затем коэффициенты оцениваются МНК.
Появление гетероскедастичности часто вызывается тем, что оценивается линейная регрессия, в то время как необходимо оценивать лог-линейную регрессию. Если обнаружена гетероскедастичность, то можно попытаться переоценить модель в логарифмической форме, особенно если содержательный аспект модели не противоречит этому. Особенно важно использование логарифмической формы, когда ощущается влияние наблюдений с большими значениями. Этот подход весьма полезен, в случае если изучаемые данные – временные ряды таких экономических переменных, как потребление, доходы, деньги, которые имеют тенденцию к экспоненциональному распределению во времени.
Рассмотрим
другой подход, например,  ,
где X
i
– независимая переменная (или какая-либо
функция независимой переменной), которая
предположительно является причиной
гетероскедастичности, а Н
отражает степень взаимосвязи между
ошибками и данной переменной, например,
Х
2
или Х
1/n
и т.д. Следовательно, дисперсия
коэффициентов запишется:
,
где X
i
– независимая переменная (или какая-либо
функция независимой переменной), которая
предположительно является причиной
гетероскедастичности, а Н
отражает степень взаимосвязи между
ошибками и данной переменной, например,
Х
2
или Х
1/n
и т.д. Следовательно, дисперсия
коэффициентов запишется:  .
Отсюда, если H=1
,
то мы трансформируем регрессионную
модель к виду:
.
Отсюда, если H=1
,
то мы трансформируем регрессионную
модель к виду:  .
Если Н=2, то есть дисперсия увеличивается
в пропорции к квадрату рассматриваемой
переменой Х, трансформация приобретает
вид:
.
Если Н=2, то есть дисперсия увеличивается
в пропорции к квадрату рассматриваемой
переменой Х, трансформация приобретает
вид:  .
.
Разберем
пример с проверкой гетероскедастичности
в модели, построенной по данным примера
из параграфа 3.2. Для визуального контроля
гетероскедастичности построим график
остатков и предсказанных значений
 .
.

Рис.8. График распределения остатков модели, построенной по данным примера
На
первый взгляд график не обнаруживает
наличия зависимости между значениями
остатков модели и
 .
Для более точной проверки рассчитаем
регрессию, в которой остатки модели,
возведенные в квадрат, - зависимая
переменная, а
.
Для более точной проверки рассчитаем
регрессию, в которой остатки модели,
возведенные в квадрат, - зависимая
переменная, а -
независимая:
-
независимая: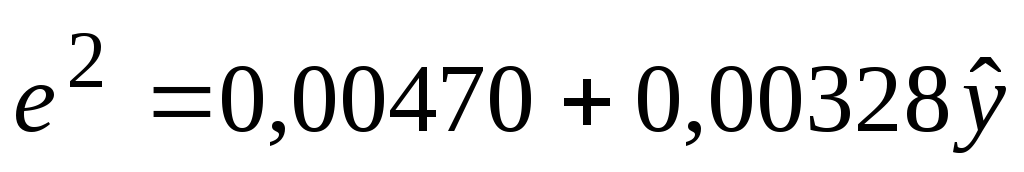 .
Значение стандартной ошибки оценки
равно 0,00408,
.
Значение стандартной ошибки оценки
равно 0,00408, =0,027,
отсюда
=0,027,
отсюда =250,027=0,625.
Табличное значение
=250,027=0,625.
Табличное значение
 =2,71.
Таким образом, нуль-гипотеза, о том, что
ошибка регрессионного уравнения имеет
постоянную дисперсию, не отклоняется
на 10% уровне значимости.
=2,71.
Таким образом, нуль-гипотеза, о том, что
ошибка регрессионного уравнения имеет
постоянную дисперсию, не отклоняется
на 10% уровне значимости.
В современных компьютерных пакетах по регрессионному анализу предусмотрены специальные процедуры диагностики гетераскедастичности и её устранения.
Если выбранная в качестве объясняющей переменной величина представляет собой действительно доминирующий фактор, то соответствующая парная регрессия достаточно полно описывает механизм причинно-следственной связи. Часто изменение y связано с влиянием не одного, а нескольких факторов. В этом случае в уравнение регрессии вводятся несколько объясняющих переменных. Такая регрессия называется множественной. Уравнение множественной регрессии позволяет лучше, полнее объяснить поведение зависимой переменной, чем парная регрессия, кроме того, оно дает возможность сопоставить эффективность влияния различных факторов.
Линейная модель множественной регрессии имеет вид:
где m – количество включенных в модель факторов. Коэффициент регрессии показывает, на какую величину в среднем изменится результативный признак y , если переменную увеличить на единицу измерения, т.е. является нормативным коэффициентом.
Уравнение линейной модели множественной регрессии в матричном виде имеет вид:
![]() , (7.11)
, (7.11)
где Y n х1 наблюдаемых значений зависимой переменной;
X – матрица размерности n х(m+1) наблюдаемых значений независимых переменных (дополнительно вводится фактор, состоящий из одних единиц для вычисления свободного члена);
α – вектор-столбец размерности (m+1) х1 неизвестных, подлежащих оценке коэффициентов регрессии;
ε – вектор-столбец размерности n х1 случайных отклонений.
Таким образом,
, , ,.
, ,.
При применении МНК относительно случайной составляющей в модели (7.10) принимаются предположения, которые являются аналогами предположений, сделанных выше для МНК, применяемого при оценивании параметров парной регрессии. Обычно предполагается:
1. ![]() - детерминированные переменные.
- детерминированные переменные.
2. ![]() - математическое ожидание случайной составляющей в любом наблюдении равно нулю.
- математическое ожидание случайной составляющей в любом наблюдении равно нулю.
3. - дисперсия случайного члена постоянна для всех наблюдений.
4. - в любых двух наблюдениях отсутствует систематическая связь между значениями случайной составляющей.
5. ~ - часто добавляется условие о нормальности распределения случайного члена.
Модель линейной множественной регрессии, для которой выполняются данные предпосылки, называется классической нормальной регрессионной моделью (Classical Normal Regression model).
Гипотезы, лежащие в основе модели множественной регрессии удобно записать в матричной форме:
1. Х – детерминированная матрица, имеет максимальный ранг (m+1)
, ρ(Х)=m+1
3,4. ![]() , где I n
– единичная матрица размером n
xn
. Так как ε
- вектор-столбец, размерности n
х1
, а ε Т
– вектор-строка, произведение εε Т
есть симметрическая матрица порядка n
. Матрица ковариаций:
, где I n
– единичная матрица размером n
xn
. Так как ε
- вектор-столбец, размерности n
х1
, а ε Т
– вектор-строка, произведение εε Т
есть симметрическая матрица порядка n
. Матрица ковариаций:
 ,
,
Элементы, стоящие на главной диагонали, свидетельствуют о том, что для всех i , это означает, что все имеют постоянную дисперсию . Элементы, не стоящие на главной диагонали дают нам для , так что значения попарно некоррелированы.
В предыдущих разделах было упомянуто о том, что вряд ли выбранная независимая переменная является единственным фактором, который повлияет на зависимую переменную. В большинстве случаев мы можем идентифицировать более одного фактора, способного влиять каким-то образом на зависимую переменную. Так, например, разумно предположить, что расходы цеха будут определяться количеством отработанных часов, использованного сырья, количеством произведенной продукции. По видимому, нужно использовать все факторы, которые мы перечислили для того, чтобы предсказать расходы цеха. Мы можем собрать данные об издержках, отработанном времени, использованном сырье и т.д. за неделю или за месяц Но мы не сможем исследовать природу связи между издержками и всеми другими переменными посредством корреляционной диаграммы. Начнем с предположений о линейной связи, и только если это предположение будет неприемлимо, попробуем использовать нелинейную модель. Линейная модель для множественной регрессии:
Вариация у объясняется вариацией всех независимых переменных, которые в идеале должны быть независимы друг от друга. Например, если мы решим использовать пять независимых переменных, то модель будет следующей:
Как и в случае простой линейной регрессии мы получаем по выборке оценки и т.д. Наилучшая линия для выборки:
Коэффициент а и коэффициенты регрессии вычисляются с помощью минимальности суммы квадратов ошибок Для дальнейшего регрессионной модели используют следующие предположения об ошибка любого данного
2. Дисперсия равна и одинакова для всех х.
3. Ошибки независимы друг от друга.
Эти предположения те же, что и в случае простой регрессии. Однако в случае они ведут к очень сложным вычислениям. К счастью, выполня вычисления, позволяя нам сосредоточиться на интерпретации и оценке торной модели. В следующем разделе мы определим шаги, которые необх предпринять в случае множественной регрессии, но в любом случае мы полагаться на компьютер.
ШАГ 1. ПОДГОТОВКА ИСХОДНЫХ ДАННЫХ
Первый шаг обычно предполагает обдумать, как зависимая переменная быть связана с каждой из независимых переменных. Нет смысла нительные переменные х, если они не дают возможность объяснения вариа Вспомним, что наша задача состоит в объяснить вариацию изменения независимой переменкой х. Нам необходимо рассчитать коэффид корреляции для всех пар переменных при условии независимости наблк друг от друга. Это даст нам возможность определить, связаны х с у линей! же нет, независимы ли между собой. Это важно в множественной регр Мы можем вычислить каждый из коэффициентов корреляции, как пока: разделе 8.5, чтобы посмотреть, насколько их значения отличны от нуля нужно выяснить, нет ли высокой корреляции между значениями незавю переменных. Если мы обнаружим высокую корреляцию, например, между х то маловероятно, что обе эти переменные должны быть включены в оконч модель.
ШАГ 2. ОПРЕДЕНИЕ ВСЕХ СТАТИСТИЧЕСКИ ЗНАЧИМЫХ МОДЕЛ
Мы можем исследовать линейную связь между у и любой комбинацией переменных. Но модель имеет силу только в том случае, если значимая линейная связь между у и всеми х и если каждый коэффи регрессии значимо отличен от нуля.
Мы можем оценить значимость модели в целом, используя того, мы должны использовать -критерий для каждого коэффициента регр чтобы определить, значимо ли он отличен от нуля. Если коэффициент сии не значимо отличается от нуля, то соответствующая независимая перем не помогает в прогнозе значения у и модель не имеет силы.
Полная процедура заключается в том, чтобы установить множествениу нейную регрессионную модель для всех комбинаций независимых переме. Оценим каждую модель, используя F-критерий для модели в целом и -кри для каждого коэффициента регрессии. Если F-критерий или любой из -кря! незначимы, то эта модель не имеет силы и не может быть использована.
модели исключаются из рассмотрения. Этот процесс занимает очень много времени. Например, если у нас имеются пять независимых переменных, то возможно построение 31 модели: одна модель со всеми пятью переменными, пять моделей, включающие четыре из пяти переменных, десять - с тремя переменными, десять - с двумя переменными и пять моделей с одной.
Можно получить множественную регрессию не исключая последовательно независимые переменные, а расширяя их круг. В в этом случае мы начинаем с построения простых регрессий для каждой из независимых переменных поочередно. Мы выбираем лучшую из этих регрессий, т.е. с наивысшим коэффициентом корреляции, затем добавляем к этому, наиболее приемлемому значению переменной у вторую переменную. Этот метод построения множественной регрессии называется прямым.
Обратный метод начинается с исследования модели, включающей все независимые переменные; в нижеприведенном примере их пять. Переменная, которая дает наименьший вклад в общую модель, исключается из рассмотрения, остается только четыре переменных. Для этих четырех переменных определяется линейная модель. Если же эта модель не верна, исключается еще одна переменная, дающая наименьший вклад, остается три переменных. И этот процесс повторяется со следующими переменными. Каждый раз, когда исключается новая переменная, нужно проверять, чтобы значимая переменная не была удалена. Все эти действия нужно производить с большим вниманием, так как можно неосторожно исключить нужную, значимую модель из рассмотрения.
Не важно, какой именно метод используется, может быть несколько значимых моделей и каждая из них может иметь огромное значение.
ШАГ 3. ВЫБОР ЛУЧШЕЙ МОДЕЛИ ИЗ ВСЕХ ЗНАЧИМЫХ МОДЕЛЕЙ
Эта процедура может бьгть рассмотрена с помощью примера, в котором определились три важнейших модели. Первоначально было пять независимых переменных но три из них - - исключены из всех моделей. Эти переменные не помогают в прогнозировании у.
Поэтому значимыми моделями оказались:
Модель 1: у прогнозируется только
Модель 2: у прогнозируется только
Модель 3: у прогнозируется вместе.
Для того, чтобы сделать выбор из этих моделей, проверим значения коэффициента корреляции и стандартного отклонения остатков Коэффициент множественной корреляции - есть отношение "объясненной" вариации у к общей вариации у и вычисляется так же, как и коэффициент парной корреляции для простой регрессии при двух переменных. Модель, которая описывает связь между у и несколькими значениями х, имеет множественный коэффициент корреляции который близок к и значение очень мало. Коэффициент детерминации который часто предлагается в ППП, описывает процент изменяемости у, которая обменяется моделью. Модель имеет значение в том случае, когда близко к 100%.
В данном примере мы просто выбираем модель с наибольшим значением и наименьшим значением Предпочтительной моделью оказалась модель следующем шаге необходимо сравнить модели 1 и 3. Различие между этими моделями состоит во включении переменной в модель 3. Вопрос в том повышает ли значительно точность предсказания значения у или же нет! Следующий критерий поможет ответить нам на этот вопрос - это частный F-критерий. Рассмотрим пример, иллюстрирующий всю процедуру построения множественной регрессии.
Пример 8.2. Руководство большой шоколадной фабрики заинтересовано в построении модели для того, чтобы предсказать реализацию одной из своих уже долго существующих торговых марок. Были собраны следующие данные.
Таблица 8.5. Построение модели для прогноза объема реализации (см. скан)
Для того чтобы модель была полезной и имела силу, мы должны отвергнуть Но и принять Значение F-критерия есть соотношение двух величин, описанных выше:
Этот критерий с одним хвостом (односторонний), потому, что средний квадрат, обусловленный регрессией, должен быть больше, чтобы мы могли принять . В предыдущих разделах, когда мы использовали F-критерий, критерии были двусторонние, так как во главу угла ставилось большее значение вариации, каким бы оно ни было. В регрессионном анализе нет выбора - наверху (в числителе) всегда вариация у по регрессии. Если она меньше, чем вариация по остаточной величине, мы принимает Но, так как модель не объясняет изменений у. Это значение F-критерия сравнивается с табличным:
![]()
Из таблиц стандартного распределения F-критерия:
![]()
В нашем примере значение критерия:
Поэтому мы получили результат с высокой достоверностью.
Проверим каждое из значений коэффициентов регрессии. Предположим, что компьютер сосчитал все необходимые -критерии. Для первого коэффициента гипотезы формулируются так:
Время не помогает объяснить изменение продаж при условии, что остальные переменные присутствуют в модели, т.е.
Время дает существенный вклад и должно быть включено в модель, т. е.
Проведем испытание гипотезы на -ном уровне, пользуясь двусторонним -критерием при:
Граничные значения на данном уровне:
![]()
Значение критерия:

Рассчитанные значения -критерия должны лежать вне указанных границ для того, чтобы мы смогли отвергнуть гипотезу

Рис. 8.20. Распределение остатков для модели с двумя переменными
Оказалось восемь ошибок с отклонениями 10% или более от фактического объема продаж. Наибольшая из них - 27%. Будет ли размер ошибки принят компанией при планировании деятельности? Ответ на этот вопрос будет зависеть от степени надежности других методов.
8.7. НЕЛИНЕЙНЫЕ СВЯЗИ
Вернемся к ситуации, когда у нас всего две переменные, но связь между ними нелинейная. На практике многие связи между переменными являются криволинейными. Например, связь может быть выражена уравнением:
![]()
![]()
Если связь между переменными сильная, т.е. отклонение от криволинейной модели относительно небольшое, то мы сможем догадаться о природе наилучшей модели по диаграмме (полю корреляции). Однако трудно применить нелинейную модель к выборочной совокупности. Было бы легче, если бы мы могли манипулировать нелинейной моделью в линейной форме. В первых двух записанных моделях функциям могут быть присвоены разные имена, и тогда будет использоваться множественная модель регрессии. Например, если модель:
лучше всего описывает связь между у и х, то перепишем нашу модель, используя независимые переменные
Эти переменные рассматриваются как обыкновенные независимые переменные, даже если мы знаем, что и х не могут быть независимы друг от друга. Лучшая модель выбирается так же, как и в предыдущем разделе.
Третья и четвертая модели рассматриваются по-другому. Тут мы уже встречаемся с необходимостью так называемой линейной трансформации. Например, если связь
![]()
то на графике это будет изображено кривой линией. Все необходимые действия могут быть представлены следующим образом:
Таблица 8.10. Расчет


Рис. 8.21. Нелинейная связь
Линейная модель, при трансформированной связи:
![]()

Рис. 8.22. Линейная трансформация связи
В общем, если исходная диаграмма показывает, что связь может быть изображена в форме: то представление у против X, где определит прямую линию. Воспользуемся простой линейной регрессией для установления модели: Рассчитанные значения а и - лучшие значения а и (5.
Четвертая модель, приведенная выше, включает трансформацию у с использованием натурального логарифма:
Взяв логарифмы по обеих сторон уравнения, получим:
поэтому: где
Если , то - уравнение линейной связи между Y и х. Пусть - связь между у и х, тогда мы должны трансформировать каждое значение у взятием логарифма по е. Определяем простую линейную регрессию по х для того, чтобы найти значения А и Антилогарифм записан ниже.
Таким образом, метод линейной регрессии может быть применен к нелинейным связям. Однако в этом случае требуется алгебраическое преобразование при записи исходной модели.
Пример 8.3. Следующая таблица содержит данные об общем годовом объеме производства промышленной продукции в определенной стране за период
Классический метод наименьших квадратов (МНК) для модели множественной регрессии. Свойства оценок МНК для модели множественной регрессии и показатели качества подбора регрессии: коэффициент множественной корреляции, коэффициенты частной корреляции, коэффициент множественной детерминации
Мультиколлинеарность факторов. Признаки мультиколлинеарности и способы ее устранения. Гомоскедастичность и гетероскедастичность остатков. Графический метод обнаружения гетероскедастичности. Причины и последствия гетероскедастичности.
МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
На любой экономический показатель чаще всего оказывает влияние не один, а несколько факторов. В этом случае вместо парной регрессии рассматривается множественная регрессия
Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и в ряде других вопросов экономики. Сегодня множественная регрессия – один из наиболее распространенных методов в эконометрике. Основной целью множественной регрессии является построение модели с большим числом факторов, а также определение влияния каждого фактора в отдельности и совокупного их воздействия на моделируемый показатель.
Множественный регрессионный анализ является развитием парного регрессионного анализа в случаях, когда зависимая переменная связана более чем с одной независимой переменной. Большая часть анализа является непосредственным расширением парной регрессионной модели, но здесь также появляются и некоторые новые проблемы, из которых следует выделить две. Первая проблема касается исследования влияния конкретной независимой переменной на зависимую переменную, а также разграничения её воздействия и воздействий других независимых переменных. Второй важной проблемой является спецификация модели, которая состоит в том, что крайне важно ответить на вопрос, какие факторы следует включить в регрессию (1), а какие – исключить из неё.
Самой употребляемой и наиболее простой из моделей множественной регрессии является линейная модель множественной регрессии:
Параметр α принято называть свободным членом и определяет значение y в случае, когда все объясняющие переменные равны нулю. При этом, как и в случае парной регрессии, факторы по своему экономическому содержанию часто не могут принимать нулевых значений, и значение свободного члена не имеет экономического смысла. При этом, в отличие от парной регрессии, значение каждого регрессионного коэффициента равно среднему изменению y при увеличении x j на одну единицу лишь при условии, что все остальные факторы остались неизменными. Величина ε представляет собой случайную ошибку регрессионной зависимости.
Получение оценок параметров ![]() уравнения регрессии (2) – одна из важнейших задач множественного регрессионного анализа. Самым распространенным методом решения этой задачи является метод наименьших квадратов (МНК). Его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной y
от её значений , получаемых по уравнению регрессии.
уравнения регрессии (2) – одна из важнейших задач множественного регрессионного анализа. Самым распространенным методом решения этой задачи является метод наименьших квадратов (МНК). Его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной y
от её значений , получаемых по уравнению регрессии.
Пусть имеется n наблюдений объясняющих переменных и соответствующих им значений результативного признака:
Для однозначного определения значений параметров уравнения (4) объём выборки n должен быть не меньше количества параметров, ᴛ.ᴇ. . В противном случае значения параметров не бывают определены однозначно. В случае если n=p +1, оценки параметров рассчитываются единственным образом без МНК простой подстановкой значений (5) в выражение (4). Получается система (p +1) уравнений с таким же количеством неизвестных, которая решается любым способом, применяемым к системам линейных алгебраических уравнений (СЛАУ). При этом с точки зрения статистического подхода такое решение задачи является ненадежным, поскольку измеренные значения переменных (5) содержат различные виды погрешностей. По этой причине для получения надежных оценок параметров уравнения (4) объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при x j в уравнении (4) в 6-7 раз.
Линейная модель множественной регрессии - понятие и виды. Классификация и особенности категории "Линейная модель множественной регрессии" 2017, 2018.