С одной стороны, величина выборочной совокупности должна быть статистически значимой, т. е. достаточно большой, для того, чтобы получить достоверную информацию. С другой стороны, выборка должна быть «экономной», т. е. оптимальной.
Каков же критерий оптимальности?
Математики считают, что таким критерием является числовые значения контрольных признаков респондентов (пол, возраст, стаж и т. д.), точнее их дисперсия (разброс). Напомним, что формы расчета дисперсии и другие формулы расчета выборки студенты проходят на занятиях по математике и статистике. Итак, чем больше дисперсия, тем больший объем выборки потребуется. Допустим, мы осуществляем отбор из генеральной совокупности в 2000 человек по признаку «пол»: 70% - мужчин и 30% - женщин. Согласно теории вероятности, можно предположить, что примерно, из каждых десяти отбираемых респондентов встретится 3 женщины. Если, например, мы хотим опросить 90 женщин, нам необходимо опросить 300 человек.
Когда информация о признаках элементов генеральной совокупности отсутствует, исключается возможность определения объема выборки при помощи формул.
В этом случае можно опереться на многолетний опыт социологов – практиков, свидетельствующий о том, что для пробных опросов достаточна выборка объемом 100-250 человек.
При массовых опросах , если величина генеральной совокупности составляет менее 5000 человек, достаточный объем выборки не менее 500 человек. Если же величина генеральной совокупности 5000 человек и более, то выборка должна быть не менее 10% ее состава, но не более 2000-2500 человек. Это гарантирует достаточно достоверные результаты.
Для телефонных опросов даже в крупных городах достаточна выборка в 100 максимум 300 респондентов.
Определение объема выборки
При проведении устных опросов целесообразно использовать метод случайной бесповоротной выборки (его суть заключается в том, что респондент отбирается случайно и второй раз уже не опрашивается). Формула выборки при этом такова:
, где
n – объем выборки;
t – коэффициент доверия, вычисляемый по таблицам в зависимости от вероятности, с которой можно гарантировать, что предельная ошибка не превысит t-кратную среднюю ошибку (при вероятности 0,990 он равен 3, а при вероятности 0,999 он равен –3, 28; чаще всего опираются на вероятность 0,954, при которой t составляет 2);
s - среднеквадратическое отклонение в генеральной совокупности или дисперсия;
Предельная (задаваемая) ошибка выборки;
N – численность генеральной совокупности.
Например, объем генеральной совокупности – 50771 человек;
· при уровне доверительной вероятности 95%, коэффициент доверия t =2
· среднеквадратическом отклонении s =50;
· и предельной ошибке выборки =7;
· объем выборки n = 203 чел.
Пример . Предположим, что магазин обслуживает за определенный период около 100 000 человек. По данным предыдущих опросов установлено, что дисперсия составляет ± 25 руб./чел. Коэффициент доверия равен 2. Предельную ошибку мы приняли равной 1 руб. Тогда численность выборки составит чел.
Следовательно, для получения надежных представительных данных надо опросить 100 чел.
В целях получения однородности изучаемой совокупности и общей точности расчета совокупность стратифицируют, разбивают на ряд групп по какому-то признаку, например по полу, доходу и т.д. Здесь формула выборки отличается от предыдущей только тем, что выборочная дисперсия заменяется средней из внутригрупповых дисперсий. Однако в этом случае целесообразно вести отбор по каждой группе пропорционально дифференциации признака (ni ). Тогда формула выборки (по каждой группе) значительно упрощается:
где k – число i -х групп населения;
Ni – численность i -й группы населения;
- среднеквадратическое отклонение признака в i- группе.
Пример. Для обследования, ставящего целью выявить мнение потребителей о новом товаре в населенном пункте, насчитывающем 50тыс. семей, необходимо провести анкетирование. Условно принимается, что в каждой квартире проживает одна семья и на нее будет выделена одна анкета. Предварительные исследования установили, что дисперсия среднего размера покупки составляет ± 25 руб.; t = 2; предельная ошибка не должна превышать 0,01 тыс. руб. Отсюда численность выборки составила:
Эта величина округляется до 1000 семей, т.е. установлена 2%-ная выборка.
Используются в практике расчета выборки и другие формулы:
Для малых массивов используется другая формула:
![]()
Ошибки выборки
Ошибки выборки бывают случайные (систематические) и ошибки смещения.
Случайные ошибки . Если отклонение полученных результатов в ту или иную сторону не превышает в среднем 5%, то выборка является репрезентативной, а ошибка случайной. Например, из соотношения генеральной совокупности 40% женщин 60% мужчин в выборку должны попасть 40% женщин 60% мужчин, а попало, например, 37% женщин и 62% мужчин, или 42% женщин и 58% мужчин. Указанные ошибки считаются случайными, т. к. они не превышают 5% барьера.
Ошибки смещения . Ошибки смещения – это более сложные ошибки. Например, в нашем примере вместо желаемых иметь в выборке 40% женщин и 60% мужчин, мы получаем, наоборот, 60% женщин и 40% мужчин. Проблема заключается в том, что рассчитать с помощью формул ошибки смещения невозможно, и они автоматически переходят на результаты и выводы исследования. Ошибки смещения могут являться следствием:
Неверных исходных статистических данных о параметрах контрольных признаков генеральной совокупности;
Слишком малого объема выборки;
Неверного применения способа отбора единиц анализа (например, отбор из неверно составленного списка, неудачный выбор места и времени проведения исследования).
При формировании выборочных совокупностей следует добиваться полноты, точности, адекватности, репрезентативности.
Полнота означает, что в генеральной совокупности должны быть представлены все единицы анализа, ибо неполнота ведет к ошибкам.
Точность характеризует информацию по каждой единице. Точность, например, считается достаточной, если сумма погрешностей и ошибок не превышает 5 %.
Адекватность есть свойство основы выборки. Довольно часто точность выборки отождествляется с ее адекватностью. Между тем это не так. Адекватность же подразумевает характеристику выборки как модели качества исследуемого объекта. Например, список молодых рабочих не может быть основой для выборки всех членов трудового коллектива. В этом случае основа выборки является неадекватной. И, наоборот, список членов трудового коллектива не может быть основой выборки для исследования молодых рабочих.
Свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Репрезентативност ь (представительность) выборки означает, что у всех элементов генеральной совокупности был шанс попасть в выборку, и что выборка отражает генеральную совокупность.
В завершение темы представим стандартные таблицы выборки с учетом предельной ошибки выборки и доверительной вероятности, разработанные социологами - практиками (табл.5).
Таблица 5
Стандартные таблицы выборки
В каждой профессии есть свой набор любимых вопросов. Для исследователей рынка этот список возглавляет, безусловно, вопрос о размере выборки. Обычно его формулируют так:
- Мы хотели бы заказать исследование по посетителям московских торговых центров. Какая нам нужна выборка?
- Наша целевая аудитория – примерно 300 000 человек. Сколько людей нам нужно опросить, чтобы было репрезентативно? А если целевая аудитория будет 3 млн?
- Нам нужно оценить потенциал продаж квартир в Санкт-Петербурге жителям северных городов России. Какую сделать выборку?
Главное заблуждение о размере выборки
Многие уверены, что чем больше размер целевой группы, тем больше должен быть размер выборки. Поэтому, якобы, чтобы узнать мнение жителей маленького города, достаточно опросить человек 200-300, ну а для выяснения мнения по России в целом и 5000 будет мало.
Между тем, этот стереотип не имеет ничего общего с реальностью. Размер выборки не зависит от численности целевой группы (на языке статистики она называется «генеральной совокупностью») и определяется двумя совершенно другими факторами. Единственное исключение из этого правила – случаи, когда генеральная совокупность очень маленькая, например, 1-2 тысячи человек, но такие ситуации в реальной практике маркетинговых исследований встречаются редко.
Два фактора, от которых зависит размер выборки
Размер выборки массового опроса зависит от двух факторов:
- Точности данных, которые нужно получить на выходе – это та самая «статистическая погрешность». Для выборки в 100 респондентов она будет в пределах плюс-минус 10%, а для выборки в 1000 респондентов – в пределах плюс-минус 3,1%. Более подробно об этом – ниже.
- Количества и размера подгрупп, на которые нужно разбивать выборку при анализе. Например, если проводится электоральное исследование, то в основном нас будет интересовать ядро активных избирателей. Как правило, доля «ядра» редко превышает 20-25% от всего населения. Поэтому размер выборки нужно рассчитывать так, чтобы одна четверть от ее общего объема позволяла проводить полноценный статистический анализ.
Две разновидности ошибки выборки
Любое выборочное наблюдение (то есть когда мы опрашиваем не всех подряд, а делаем случайный отбор из генеральной совокупности) сопряжено с погрешностью данных. Эту погрешность обычно называют «ошибкой выборки». Она может быть двух видов:
- Систематическая – связана с ошибками проектирования выборки. Оценить ее размер, направление и степень смещения очень сложно, чаще всего – невозможно. Например, если вопросы респондентам будут задавать представители маргинальных социальных слоев, это повлияет на готовность участвовать в исследовании со стороны представителей более обеспеченных групп населения. В итоге это приведет к крайне трудно оцениваемой систематической ошибке и искажению данных.
- Случайная – связана с действием законов статистики. Ее размер легко рассчитывается по формулам математической статистики и теории вероятности. Они позволяют делать обоснованные выводы о доверительном интервале признака. Например, если статистическая погрешность составляет плюс-минус 10%, а полученное значение показателя оказалось равно 25%, то доверительный интервал равен от 15% до 35%.

Задача исследователя – собрать данные так, чтобы минимизировать систематическую ошибку выборки. Тогда можно будет свести статпогрешность лишь к случайной ошибке, которую можно рассчитать по формулам.
Как рассчитать размер случайной ошибки выборки
Случайная ошибка выборки зависит не только от объема выборки, но и от дисперсии, то есть степени однородности данных. Чем однороднее данные (т.е. чем меньше разброс полученных значений, или дисперсия), тем меньше ошибка выборки.
Существует формула расчета случайной ошибки выборки, однако для удобства рекомендуем пользоваться онлайн-калькуляторами, например, вот этим . Он позволяет легко провести два вида расчета:
- рассчитать величину статистической погрешности на основе размера выборки и предполагаемой дисперсии;
- определить размер выборки, требуемый для получения оценки нужной степени точности.

В качестве параметра доверительной надежности (одно из полей в калькуляторе) обычно используется значение в 95%. Это означает, что в 95% случаев распределение признака в генеральной совокупности попадет в рассчитанный доверительный интервал (т.е. само значение признака в выборке плюс-минус размер статистической погрешности). Реже используется значение надежности в 97% или 99% – оно, соответственно, означает, что подобное попадание произойдет в 97% или 99% случаев. В данном случае надежность выборки повышается, но увеличивается размер выборки.
Самое сложное при определении размера выборки – поиск компромисса между требуемой точностью и стоимостью сбора данных. Этот процесс усложняется тем, что увеличение размера выборки в четыре раза приводит к увеличению точности лишь в два раза (соответствует квадратному корню от величины прироста выборки).
Кейс: определение размера выборки для оценки потенциала рынка продаж столичной недвижимости покупателям из регионов
В ноябре-декабре 2016 года мы провели исследование спроса на квартиры в новостройках Москвы и Санкт-Петербурга со стороны жителей разных городов России. Исследование включало в себя три метода сбора данных: массовый репрезентативный опрос населения в возрасте от 20 до 60 лет (проводился с использованием технологии CATI), а также серию экспертных интервью с риэлторами и глубинных интервью с потенциальными покупателями квартир.
Исследование охватывало 33 города, отличающихся повышенным спросом на петербургскую и московскую недвижимость. Плановая выборка исследования, рассчитанная по формулам, составила 21 500 респондентов. Этот объем значительно больше «стандартного» объема выборки, используемого в маркетинговых исследованиях. С чем же связан такой большой размер выборки?
Все дело в том, что клиенту были нужны оценки отдельно по каждому городу, а не просто «в целом по стране». Фактически мы работаем не с 1 выборкой, а с 33 отдельными выборками по каждому городу. Доля людей, заинтересованных в покупке квартиры в Санкт-Петербурге или Москве, была экспертно определена в рамках 5% от числа жителей опрашиваемых городов.
В зависимости от важности города для заказчика, руководитель проекта со стороны Агентства определил допустимую статистическую погрешность, в которую должны укладываться итоговые результаты. Для этого мы использовали специальный макрос в MS Excel, но эти расчеты можно также выполнить с помощью калькулятора выборки. В результате размер выборки варьировал от 500 до 1000 респондентов по каждому из городов исследования, что в сумме и дало заявленные 21 500 человек.
- Определите структуру целевой группы. Планируете ли вы анализировать отдельные подгруппы или достаточно будет анализа по выборке в целом?
- Определите желаемую точность данных. Например, если нужно оценить динамику рыночной доли за год, подставьте в специальный калькулятор примерное значение доли и «поиграйте» с разными объемами выборки.
- Найдите баланс между стоимостью сбора данных (прямо пропорциональна объему выборки) и требуемой точностью.
Процедура составления плана выборки включает последовательное решение трех следующих задач:
Определение объекта исследования;
Определение структуры выборки;
Определение объема выборки.
Как правило, объект маркетингового исследования представляет собой совокупность объектов наблюдения, в качестве которых могут выступать потребители, сотрудники компании, посредники и т.д. Если эта совокупность настолько малочисленна, что исследовательская группа располагает необходимыми трудовыми, финансовыми и временными возможностями для установления контакта с каждым из ее элементов, то вполне реально проведение сплошного исследования всей совокупности. В этом случае, определив объект исследования, можно приступать к следующей процедуре (выбору метода сбора данных, орудия исследования и способа связи с аудиторией).
Однако на практике очень часто не представляется возможным или целесообразным проведение сплошного исследования всей совокупности. Для этого могут быть следующие причины:
Невозможность установления контакта с некоторыми элементами совокупности;
Неоправданно большие расходы на проведение сплошного исследования или наличие финансовых ограничений, не позволяющих проведение сплошного исследования;
Сжатые сроки, отведенные для исследования, обусловленные утратой со временем актуальности информации или другими причинами и не позволяющие осуществить сбор, систематизацию и анализ обширных данных для всей совокупности.
Поэтому большие и разбросанные совокупности часто изучаются с помощью выборки, под которой, как известно, понимается часть совокупности, призванная олицетворять совокупность в целом.
Точность, с которой выборка отражает совокупность в целом, зависит от структуры и размера выборки .
Различают два подхода к структуре выборки - вероятностный и детерминированный.
Вероятностный подход к структуре выборки предполагает, что любой элемент совокупности может быть выбран с определенной (не нулевой) вероятностью. Существуют различные виды выборок, основанных на теории вероятностей (типическая, гнездовая и др.). Наиболее простой и распространенной на практике является простая случайная выборка, при которой каждый элемент совокупности имеет равную вероятность выбора для исследования.
Вероятностная выборка более точна, позволяет исследователю оценить степень достоверности собранных им данных, хотя она сложней и дороже, чем детерминированная.
Детерминированный подход к структуре выборки предполагает, что выбор элементов совокупности производится методами, основанными либо на соображениях удобства, либо на решении исследователя, либо на контингентных группах.
на соображениях удобства , состоит в выборе любых элементов совокупности исходя из простоты установления контакта с ними. Несовершенство этого метода обусловлено, возможно, низкой репрезентативностью полученной выборки, т.к. удобные для исследователя элементы совокупности могут быть недостаточно характерными представителями совокупности в силу неслучайного и необоснованного их отбора.
Однако, с другой стороны, простота, экономичность и оперативность исследования, проводимого этим методом, снискали ему довольно широкое распространение на практике и, прежде всего при проведении предварительных исследований, направленных на уточнение основных проблем.
Метод формирования выборки, основанный на решении исследователя , состоит в выборе элементов совокупности, которые, по его мнению, являются ее характерными представителями. Этот метод является более совершенным, чем предыдущий, поскольку в его основе лежит ориентировка на характерных представителей исследуемой совокупности, хотя и подбираемых на основе субъективных представлений исследователей о ней.
Метод формирования выборки, основанный на контингентных нормах , состоит в выборе характерных элементов совокупности в соответствии с полученными ранее характеристиками совокупности в целом. Эти характеристики могут быть получены путем проведения предварительных исследований и в отличие от предыдущего метода не носят субъективного характера. Поэтому данный метод является более совершенным, он позволяет получить выборочные совокупности не менее представительные, чем вероятностные выборки при значительно меньших затратах на проведение обследования.
Выбрав структуру выборки (подход к ее формированию, вид вероятностной или метая формирования детерминированной выборки), исследователю предстоит определить объем, т.е. количество элементов выборочной совокупности.
Объем выборки определяет достоверность информации , полученной в результате ее исследования, а также необходимые для проведения исследования затраты. Объем выборки зависит от уровня однородности или разновидности изучаемых объектов.
Чем больше объем выборки, тем выше ее точность и больше затраты на проведения ее обследования. При вероятностном подходе к структуре выборки ее объем может быть определен с помощью известных статистических формул, на основе заданных требований к ее точности.
На практике используется несколько подходов к определению объема выборки:
1. Произвольный подход основан на применении «правила большого пальца». Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход является простым и легким в исполнении, однако не представляется возможным установить точность полученных результатов. При достаточно большой совокупности он к тому же может быть и весьма дорогим.
Объем выборки может быть установлен исходя из неких заранее оговоренных условий. К примеру, заказчик маркетингового исследования знает, что при изучении общественного мнения выборка обычно составляет 1000-1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры. В случае, если на каком-то рынке проводятся ежегодные исследования, то в каждом году используется выборка одного и того же объема. В отличие от первого подхода здесь при определении объема выборки используется известная логика, которая, однако, является весьма уязвимой.
Например, при проведении определенных исследований может потребоваться точность меньше, чем при изучении общественного мнения, да и объем совокупности может быть во много раз меньше, нежели при изучении общественного мнения. Таким образом, данный подход не принимает в расчет текущие обстоятельства и может быть достаточно дорогим.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать. Очевидно, что ценность получаемой информации не принимается в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Представляется разумным учитывать затраты не абсолютным образом, а по отношению к полезности информации, полученной в результате проведенных обследований. Заказчик и исследователь должны рассмотреть различные объемы выборки и методы сбора данных, затраты, учесть другие факторы
2. Объем выборки от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки (табл. 4.2).
Таблица 4.2
Расчетная таблица выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расчетам того же автора, можно указать величины фактической ошибки выборки в зависимости от ее объема, что для нас весьма важно, памятуя, что величина допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентному уровню.
Таблица 4.3
Расчетная таблица
|
Объем выборки, если генеральная совокупность 5000 | ||||||||
|
Фактическая ошибка при данном объёме выборки, % |
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
3. Объем выборки на основе статистического анализа . Этот подход основан на определении минимального объема выборки исходя из определенных требований к надежности и достоверности получаемых результатов. Он также используется при анализе полученных результатов для отдельных подгрупп, формируемых в составе выборки по полу, возрасту, уровню образования и т.п. Требования к надежности и точности результатов для отдельных подгрупп диктуют определенные требования к объему выборки в целом.
Наиболее теоретически обоснованный и корректный подход к определению объема выборки основан на расчете достоверных интервалов. Понятие вариации характеризует величину несхожести (схожести) ответов респондентов на определенный вопрос. В более строгом плане вариацией значений какого-либо признака в совокупности называется различие его значений у разных единиц данной совокупности в один и тот же период или момент времени. Результаты ответов на вопросы опроса обычно представляются в форме кривой распределения (рис. 4.1). При высокой схожести ответов говорят о малой вариации (узкая кривая распределения) и при низкой схожести ответов – о высокой вариации (широкая кривая распределения).
В качестве меры вариации обычно принимается среднее квадратическое отклонение, которое характеризует среднее расстояние от средней оценки ответов каждого респондента на определенный вопрос.
Малая вариация
Высокая вариация
Рис. 4.1. Вариация и кривые распределения
Поскольку все маркетинговые решения принимаются в условиях неопределенности, то это обстоятельство целесообразно учесть при определении объема выборки. Так как определение исследуемых величин для совокупности в узком осуществляется на основе выборочной статистики, то следует установить диапазон (доверительный интервал), в который, как ожидается, попадут оценки для совокупности в целом, и ошибку их определения.
Доверительный интервал – это диапазон, крайним точкам которого соответствует определенный процент определенных ответов на какой-то вопрос. Доверительный интервал тесно связан со средним квадратическим отклонением изучаемого признака в генеральной совокупности: чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав определенный процент ответов.
Доверительный интервал, равный или 95 %, или 99 %, является стандартным при проведении маркетинговых исследований. Ни одна фирма не проводит маркетинговых исследований, формируя несколько выборок. И математическая статистика дает возможность получить некую информацию о выборочном распределении, владея только данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, от оценки, которая ожидается для типичной выборки, является средняя квадратическая ошибка. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Когда на заданный вопрос существует только два варианта ответа, выраженные в процентах (используется процентная мера), объем выборки определяется по следующей формуле:

где n – объем выборки; z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности; p – найденная вариация для выборки; g – (100-р); е – допустимая ошибка.
При определении показателя вариации для определенной совокупности прежде всего целесообразно провести предварительный качественный анализ исследуемой совокупности, в первую очередь установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно проведение пилотного исследования, использование результатов подобных исследований, проведенных в прошлом. При использовании процентной меры изменчивости принимается в расчет то обстоятельство, что максимальная изменчивость достигается для р = 50 %, что является наихудшим случаем. К тому же этот показатель радикальным образом не влияет на объем выборки. Учитывается также мнение заказчика исследования об объеме выборки.
Возможно определение объема выборки на основе использования средних значений, а не процентных величин.

где s – среднее квадратическое отклонение.
На практике, если выборка формируется заново и схожие опросы не проводились, то s не известно. В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
 где
где
 .
.
Выше шел разговор о совокупностях очень больших размеров. Однако в ряде случаев совокупности не являются большими. Обычно, если выборка составляет менее пяти процентов от совокупности, то совокупность считается большой и расчеты проводятся по вышеприведенным правилам. Если объем выборки превышает 5 % от совокупности, то последняя считается малой и в вышеприведенные формулы вводится поправочный коэффициент.
Объем выборки в данном случае определяется следующим образом:
 ,
,
где n - объем выборки для малой совокупности; n 0 – объем выборки, рассчитанный по приведенным выше формулам; N – объем генеральной совокупности.
Очевидно, что использование выборки меньших размеров приведет к экономии времени и средств.
Приведенные формулы расчета объема выборки основаны на предположении, что все правила формирования выборки были соблюдены и единственной ошибкой выборки является ошибка, обусловленная ее объемом. Однако, следует помнить, что объем выборки определяет точность полученных результатов, но не их представительность.
Последняя определяется методом формирования выборки. Все формулы для расчета объема выборки предполагают, что репрезентативность гарантируется использованием корректных вероятностных процедур формирования выборки.
Объем, выборки определяется аналитическими, задачами исследования, а ее репрезентативность - целевой установкой программы. Именно программа задает образ необходимой генеральной совокупности для проведения выборки. Будет ли это все население или особые его структурные образования, все элементы изучаемого объекта или только выделяемые по заданным программой критериям, генеральную совокупность составляют все единицы, определенного в программе объекта.
При детерминированном подхода к структуре выборки в общем случае не представляется возможным расчетным путем точно определить ее объем в соответствии с заданным критерием достоверности полученной информации. В этом случае объем выборки может быть определен эмпирически. Ориентиром здесь может служить опыт проведения маркетинговых исследований за рубежом. Так, при обследовании покупателей высокая точность выборки обеспечивается, даже если ее объем не превышает 1% всей совокупности при проведении опросов покупателей средних и крупных розничных фирм, количество опрашиваемых (объем выборки), как правило, колеблется от 500 до 1000 человек.
Значение процедуры выбора метода сбора первичной информации, и орудия исследования состоит в том, что результаты этого выбора определяют как достоверность и точность подлежащей сбору информации, так и продолжительность, и дороговизну ее сбора.
Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:
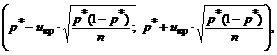
где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  | 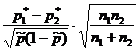 |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.